

Hopefully Not Boring Weekly AI Stuff #1
Hopefully Not Boring Weekly AI Stuff #1
The first summary of everything interesting and exciting I've found on the internet this week. Enjoy!

This week:
Mark Zuckerberg about the heart disease diagnostics model and giant test set
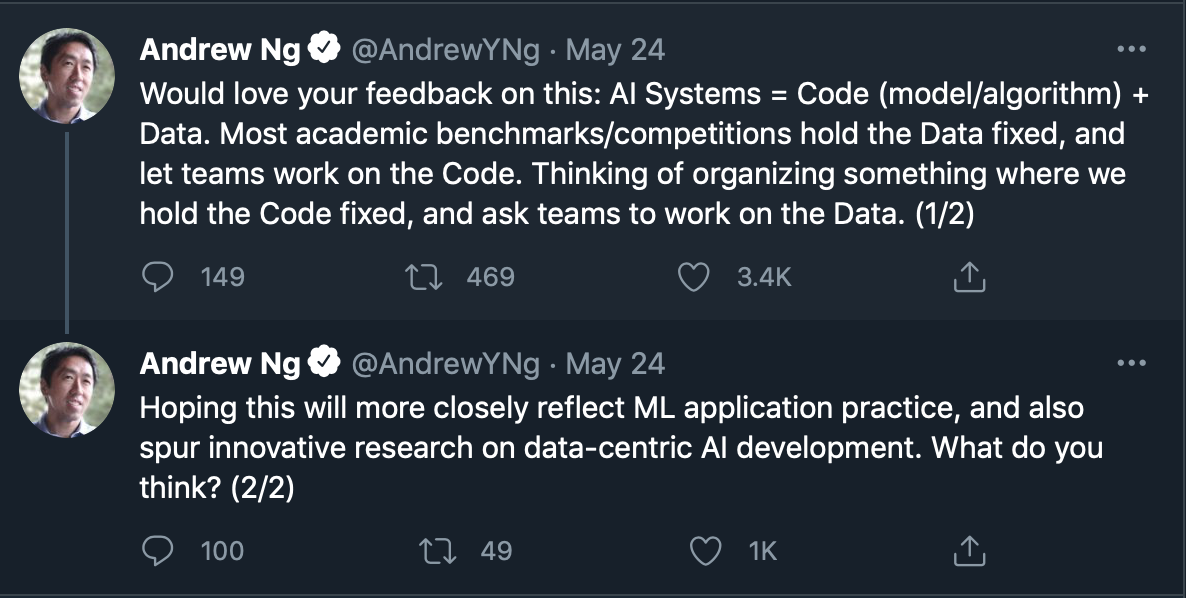
Andrew Ng about fixing code instead of data for benchmarking
Google and DeepMind relationships
Development of fit/predict style DL with Lightning Flash v0.3
Enterprise Support Program from Pytorch
Reinforcement learning of Android from DeepMind
Easy way to find Dataset loaders on Papers with Code
Enjoy!
Zuck about medicine
What: Recently Mark Zuckerberg posts about Congenital heart disease diagnostics using the DL model with high accuracy. The most interesting part is that the authors used a test set 400(!) times larger than the training set. It is quite uncommon in the DL area, but, honestly, the very right thing to do.
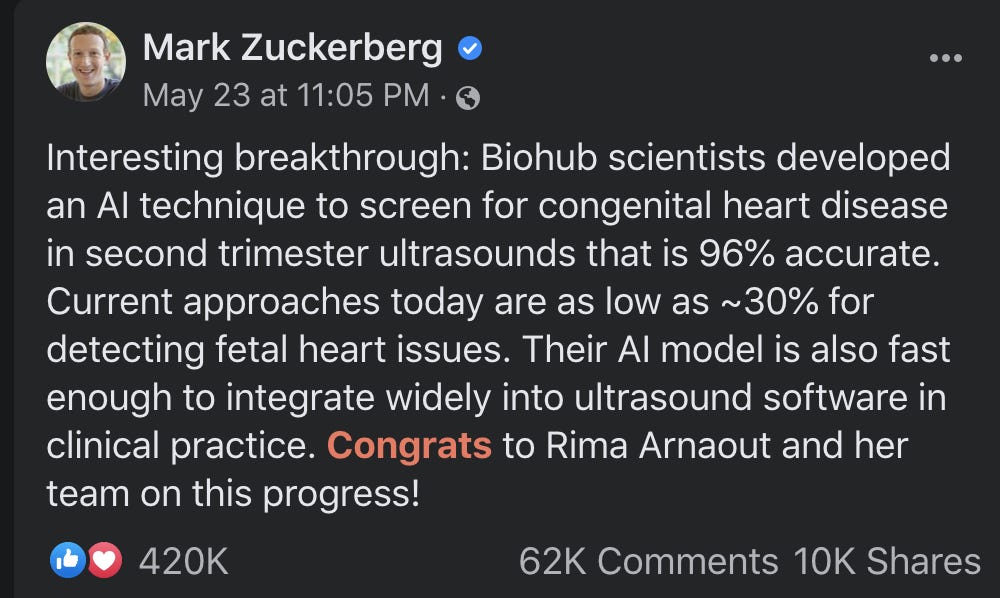
Where: The article itself is posted and medxriv: Expert-level prenatal detection of complex congenital heart disease from screening ultrasound using deep learning.
Note, medxtiv is a preprint server, meaning articles are not peer-reviewed.
Andrew Ng about data importance. Again.
What: Simple, yet important and valuable thoughts of Andrew Ng on fixing models instead of datasets in DL experiments and benchmarks. I like his ability to explain complex concepts easily. Plus, totally agree with moving to data-centric approaches. He is talking about that more and more - I bet his next course will be about data.
Yann LeCun about DeepMind
What: Chief AI Scientist at Facebook comments on complex relationships between Google and DeepMind. Google bought DM in 2014, and since then it was unclear if DM should stay a separate company or completely integrate into Google.
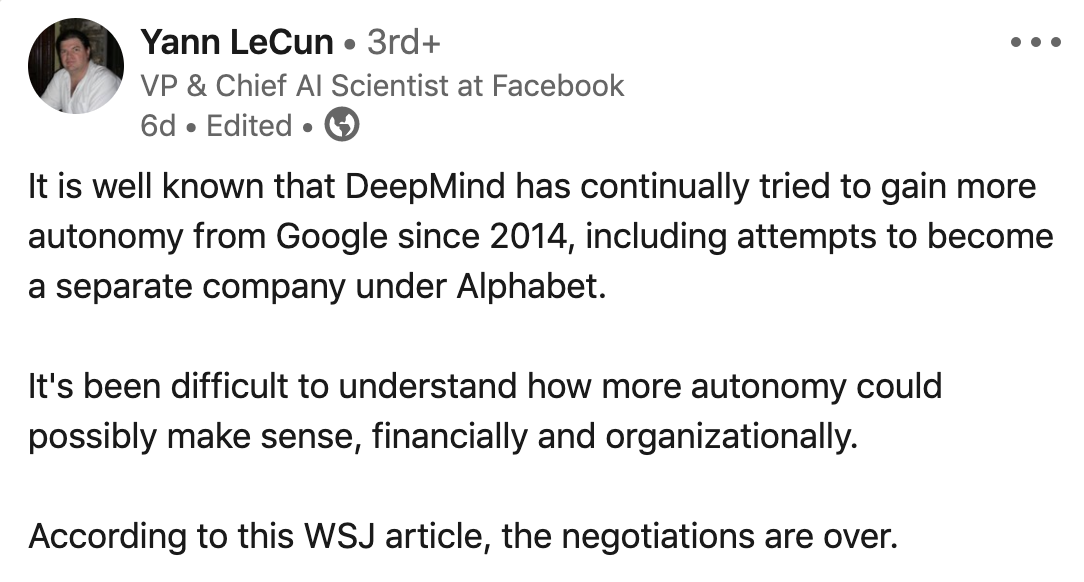
Where:
Lightning Flash v 0.3 from Pytorch-Lightning
What: A new version of wrapper over Pytorch-Lightning, which is itself wrapper over Pytorch. Flash is a nice tool for easy-peasy baselining and experimentation with a lot of pre-build SOTA methods. A good way to go for fas proofs of concepts and for people who don’t want to dive deep into Deep Learning. This field will certainly grow and we can expect something like the sklearns fit/predict in coming years.
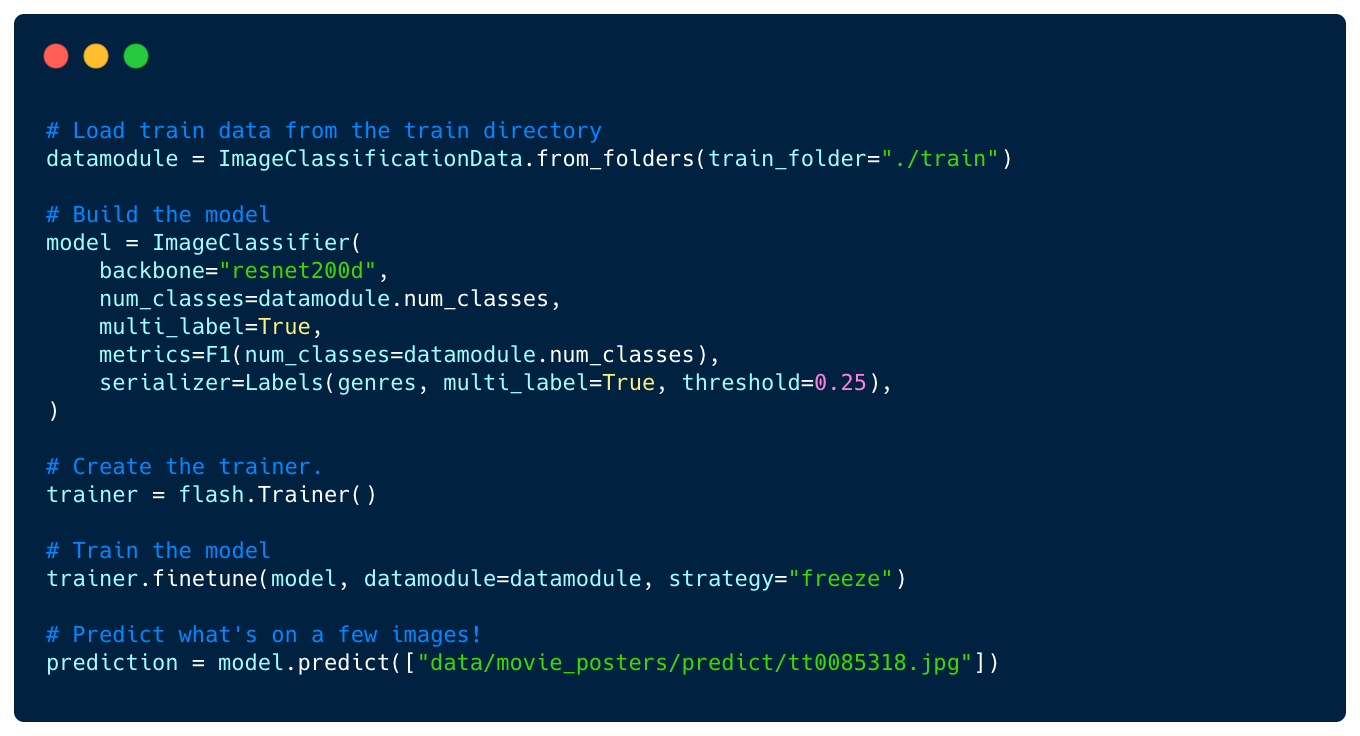
In addition to that, we have included 8 new tasks across the Computer Vision and NLP domains, visualization tools to help with debugging, and an API to facilitate the use of existing pre-trained state-of-the-art Deep Learning models.
Where:Lightning Flash 0.3 — New Tasks, Visualization Tools, Data Pipeline, and Flash Registry API
PyTorch Announcing the Enterprise Support Program
What: According to Pytorch, it is “participatory program that enables service providers to develop and offer tailored enterprise-grade support to their customers.”
This exact news is about collaboration between Facebook and Microsoft.
As one of the founding members and an inaugural member of the PyTorch Enterprise Support Program, Microsoft is launching PyTorch Enterprise on Microsoft Azure to deliver a reliable production experience for PyTorch users. Microsoft will support each PyTorch release for as long as it is current. In addition, it will support selected releases for two years, enabling a stable production experience.
A great step for Pytorch towards scalable production cloud solutions. Way to go!
Where: Announcing the PyTorch Enterprise Support Program
AndroidEnv by DeepMind
What: Reinforcement Learning (yeah, all these AlphaGo, Starcraft, etc. AI playing techniques) is coming to Android.
We're excited to introduce AndroidEnv, a platform that allows agents to interact with an Android device and solve custom tasks built on top of the Android OS. In AndroidEnv, an agent makes decisions based on images displayed on the screen, and navigates the interface through touchscreen actions and gestures just like humans.
Where: AndroidEnv: The Android Learning Environment
Dataset Loaders from Papers with Code
What: Papers with code continue to develop new nice features. After announcing a collaboration with arxiv they released an easy way to find code to load datasets. Supports huggingface datasets, TensorFlow datasets, OpenMMLab, AllenNLP, and many more. Papers with code is doing amazing job!
Where: tweet, Stanford Sentiment Treebank example
See you next week with new summary!